6.7960 Deep Learning Final Project
Music-Theory Informed Loss for Polyphonic MIDI
Generation with Transformer Diffusion Models
Introduction
AI-guided audio generation efforts have become increasingly popular, both in research and in industry [1, 2]. However, there is a key distinction between training models to generate pure audio and compose music. The process of composing true playable pieces, consisting of notes, rhythms, instruments, chords, is referred to as symbolic music generation. For symbolic music generation, models are generally trained to work with and generate MIDI (Musical Instrument Digital Interface) files, a digital score format that encodes musical events such as pitch, duration, timing, and instrument choice. Symbolic generation often focuses on polyphonic music, where multiple notes or musical lines sound simultaneously, such as in piano pieces, string quartets, or multi-track arrangements.
Most current systems represent MIDIs as a single sequence of note events, forcing the model to implicitly discover 2D structure — melodic continuity, chord consistency, and voice independence — from flattened data. Despite improvements in tokenization schemes, these models often struggle to maintain stable voice lines or valid harmonic textures. In reality, polyphonic music is inherently two-dimensional: the horizontal axis reflects how melodies evolve over time, while the vertical axis captures the harmony formed by notes sounding together at each moment. Flattening this grid into a 1D sequence obscures both dimensions, making it significantly harder for models to learn coherent melodic motion and consistent chordal structure. One framework developed by Microsoft research, GETMusic [3], addresses this issue by converting MIDI inputs into a 2D track–time image-like representation, enabling a diffusion-based transformer to model local and global musical patterns directly in two dimensions. This representation introduces a stronger inductive bias than single-stream event models, since vertical and horizontal relationships are spatially explicit rather than reconstructed from a token sequence. However, harmony in GETMusic remains an emergent property: the diffusion objective is a generic reconstruction loss that does not encode any explicit music-theoretic principles. As a result, GETMusic remains heavily dependent on extremely large MIDI datasets, and the original authors invested substantial effort in crawling and cleaning thousands of hours of symbolic music to obtain sufficient training data.
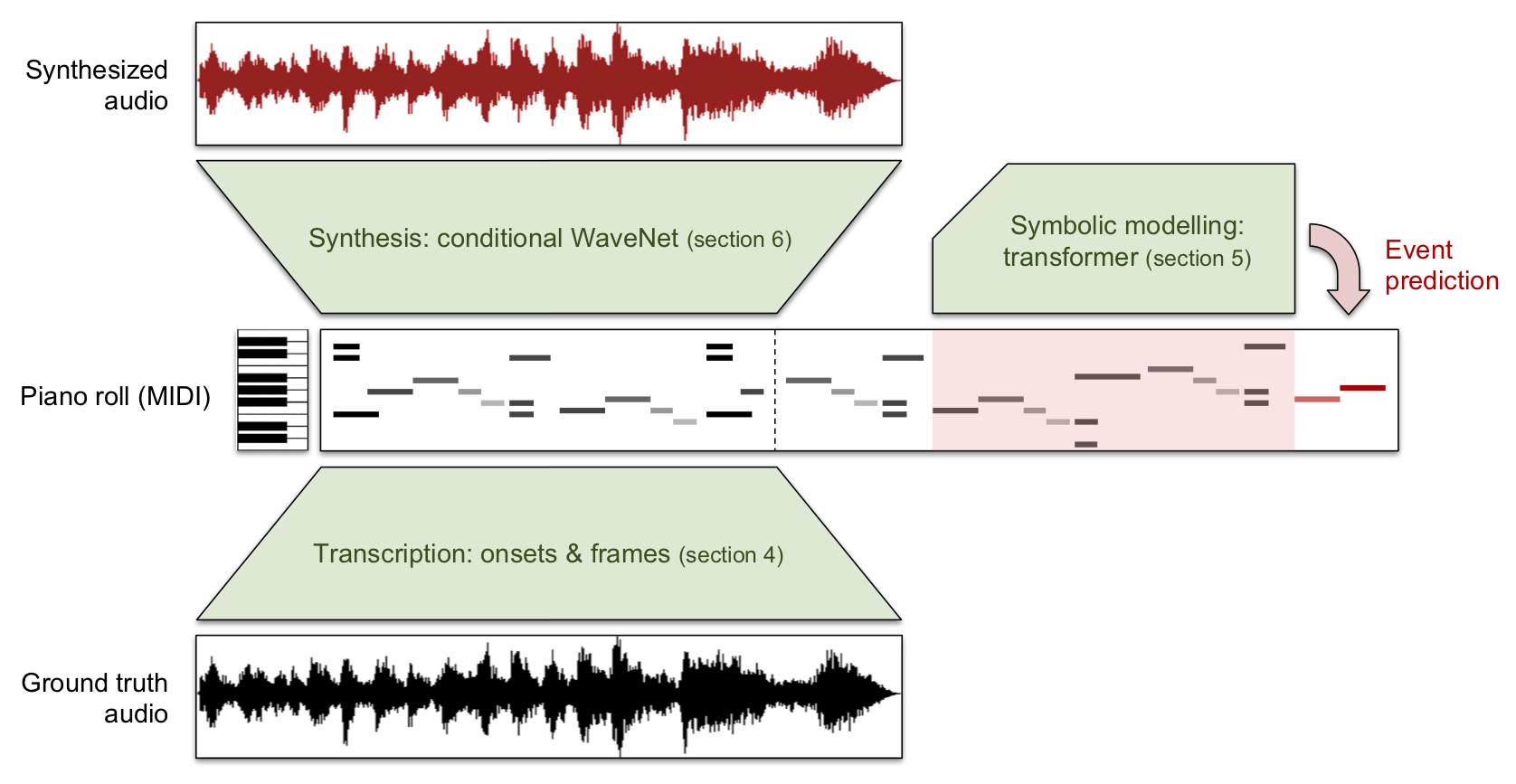
We seek to build upon the GETMusic architecture by incorporating an explicit, music-theory-informed loss regularization term into the GETMusic framework to more reliably enforce vertical harmonic constraints. By aligning the objective function with known principles of polyphonic writing, we strengthen the inductive biases already present in GETMusic’s 2D representation and reduce the dependence on massive curated datasets. We aim to produce more coherent polyphonic outcomes, especially when training resources or datasets are limited.
Background & Related Work
Sequence-based symbolic models
Early neural approaches to symbolic music generation modeled MIDI as a time-ordered sequence of events, typically using RNNs to generate monophonic or lightly polyphonic textures [4]. These models struggled to maintain long-range form, independent voices, and consistent harmonic context. When the transformer architecture was applied to music [5] for the first time in 2018, it introduced relative positional self-attention for long-range structure, but encoded all notes—across hands or tracks—as a single 1D event stream. Vertical relationships, i.e. which notes sound together at once, were implied only by co-occurring time indices in the sequence, not by a structural axis. Today, the transformer is the most commonly used architecture for MIDI generation, yet virtually all widely used architectures still rely on flattened 1D event streams, leaving multi-voice structure to be reconstructed implicitly by attention.
Some other examples of modern symbolic music generators that interpret musical input as a single stream include:
- Compound Word Transformer (CP-Transformer) [6]: Groups attributes of a single note (pitch, duration, velocity, instrument) into compound tokens, shortening sequences and slightly tightening intra-note structure, but the representation remains a flat stream of notes.
- PopMAG / MuMIDI [7]: Proposes a multi-track sequence representation where track identity and chord information are encoded as token attributes. This allows multi-track accompaniment generation but further lengthens the sequence and still interleaves tracks in one stream.
- MMM (Multi-Track Music Machine), MTMT (Multitrack Music Transformer), and Nested Music Transformer [8–10]: Encode multi-track events as tuples (instrument, pitch, duration, etc.) that are then fully flattened into a 1D sequence.
In these sequence-based models, harmony and voice-leading emerge from learned attention patterns over a long interleaved sequence. In practice, this creates well-known failure modes—voice crossing, unstable chord spacing, local dissonances, and loss of individual line identity—unless trained on a very large dataset and carefully regularized. Our work is motivated by this limitation: we aim to preserve the advantages of transformer-style modeling while moving towards representations and objectives that encode vertical structure more explicitly.
Image-based / 2D representations
A second family of methods abandons purely sequential representations and instead treats symbolic music as a 2D grid, usually a piano-roll with time on the horizontal axis and pitch on the vertical axis, sometimes with instrument tracks as channels.
- MuseGAN [11]: Generates multi-track piano-roll tensors, where each bar is represented as a binary matrix of size (time steps × pitches × tracks). Convolutional GANs operate directly on this 2D (plus channels) structure, so vertical chords and cross-track combinations are local patterns in an “image” rather than dispersed tokens, yielding strong local harmonic textures but typically limited to bar-level phrases with GAN training instabilities and weak global structure.
- MidiNet [12]: Uses convolutional GANs to generate melody one bar at a time in piano-roll form, conditioned on both 1D sequences (chords) and 2D contexts (previous bars). While the vertical axis explicitly encodes chord content, the objective is still a generic adversarial loss over images rather than a music-theoretic notion of harmony.
- DiffRoll [13]: Employs diffusion to generate piano-rolls conditioned on audio spectrograms for automatic music transcription. The model denoises a 2D time-pitch grid of symbolic events from Gaussian noise, demonstrating that diffusion in a piano-roll space can capture realistic local harmonic patterns.
GETMusic and 2D token grids
Architecturally, our work is closest to GETMusic [3], which positions itself between transformer sequence-based and image-based methods. GETMusic introduces GETScore, a 2D arrangement of discrete note tokens where tracks are stacked vertically and progress horizontally over time, with each track represented by two rows (pitch and duration). Compound pitch tokens merge simultaneous notes within a track, preserving intra-track chords while keeping the grid compact.
A discrete diffusion model, GETDiff, denoises masked target tracks conditioned on source tracks in a non-autoregressive fashion, enabling flexible any-track-to-any-track generation and zero-shot infilling. Compared to piano-roll GANs/diffusion, GETScore avoids extremely large and sparse images while still making both horizontal continuity and vertical cross-track relationships spatially explicit. Compared to 1D event models such as PopMAG, it eliminates track interleaving: tracks are temporally aligned in a score-like grid rather than interwoven in a single stream.
However, GETMusic’s objective remains a purely statistical discrete diffusion loss plus auxiliary reconstruction terms. There is no explicit bias towards music-theoretic principles beyond what is implicitly encoded in the dataset and the compound-token construction. In fact, the authors emphasize that they crawled and cleaned over 1.5M MuseScore MIDIs (around 2,800 hours of data) to train GETMusic, underscoring its dependence on very large curated datasets to learn harmonic structure robustly.
Positioning our contribution
Our project builds directly on this GETMusic line of work: we retain a 2D symbolic representation and a diffusion-style transformer backbone, but modify the learning objective by adding a music-theory-informed regularization term that explicitly evaluates the vertical slice (local harmony and spacing at each time step). Rather than treating harmony as a purely emergent property of data and generic denoising, we encode constraints derived from polyphonic writing practice—for example, penalties for certain dissonant intervals or unstable chord spacings, and rewards for consonant interval structures and consistent voice ranges—and integrate them into the loss function calculation.
Methodology & Experiments
To validate our hypothesis that explicit music-theoretic constraints can improve polyphonic generation—particularly in data-constrained environments—we implemented our proposed regularization framework on top of the GETMusic architecture. Our goal is to determine whether injecting domain-specific inductive biases into a diffusion-based symbolic music generator enables coherent harmonic structure even when trained on only a few hundred examples. We therefore conducted controlled experiments comparing the original GETMusic loss (GETM) against our proposed Music Theory Loss (MTL), using identical training conditions and evaluation metrics.
Dataset and Preprocessing
We downloaded the open source Slakh2100 dataset, which largely focuses on pop music. It contains 1500 training tracks, 375 validation tracks, and 225 test tracks. Our preprocessing pipeline consisted of three major stages:
1. Track Merging. We mapped Slakh's multi-instrument arrangements into the standardized 14-row GETScore layout (7 instruments × 2 attributes: pitch and duration). GETMusic supports the following instruments, labeled by their instrument code: '0': piano, '25':guitar, '32':bass, '48':string, '80':lead melody; along with drums and chord labels.
2. Filtering. Each MIDI file is converted into GETMusic's event-based OCT representation, where note events are assigned to a fixed grid of discrete time steps determined by the model's bar and positional resolution. This mapping ensures that notes, durations, and positions align with the model's multi-track format. After conversion, events that fall outside supported instrument types, have zero durations, or violate representation constraints are filtered out. The final encoded sequence is then chunked or padded to fit the model's maximum sequence length of 512 tokens for training.
3. Data Pruning. Tracks that lacked sufficient polyphonic content or fell below a minimum length threshold were removed. The resulting curated dataset consisted of 292 MIDI files—dramatically smaller than the 1.5M files used by the original GETMusic authors. This constrained setting is intentional: our goal is to test whether explicit harmonic regularization can compensate for limited data, a regime where standard diffusion-based systems often fail.
Architecture and the Music Theory Loss
Our backbone model is the Diffusion RoFormer (Rotary Transformer) used in the GETMusic framework. Let the logits over the discrete vocabulary at each diffusion step be denoted by
where B is the batch size, V is the vocabulary size, and L is the sequence length in the GETScore grid. The corresponding conditional distribution over clean tokens at diffusion step t is
The baseline GETMusic objective is the Variational Lower Bound (VLB) on the log-likelihood, which trains the model to reconstruct the clean token grid from the corrupted state . To encode music-theoretic structure into this process, we augment the VLB with our Music Theory Loss (MTL), obtaining the total training objective
Here, controls the strength of the music-theoretic regularization. Conceptually, GETM refers to the baseline objective , while MTL denotes our additional structured loss term .
MTL is composed of two components: a Vertical Consonance Loss enforcing harmonic stability across tracks, and a Key Adherence Loss promoting tonal coherence.
Pitch-Class Distributions
We operate on pitch-class distributions aggregated from the vocabulary-level probabilities. Let index time positions along the horizontal axis and n index tracks along the vertical axis. For each token position , we project from vocabulary space to the 12 pitch classes by summing over all vocabulary entries assigned to each pitch class via a fixed mapping matrix .
This gives us a 12-dimensional distribution over pitch classes for each track and time step, which we use in both components of the Music Theory Loss.
Training Progress
We trained both our modified architecture and the baseline MIDI generation model on a preprocessed collection of 292 MIDI files from slakh-2100, resulting in 1650 trainable segments of audio. We ran 50 epochs with 546 iterations per epoch. We also made use of a validation set during training. The following plots show the training and validation loss curves for both the baseline GETMusic model and our Music Theory Loss variant over the course of training.
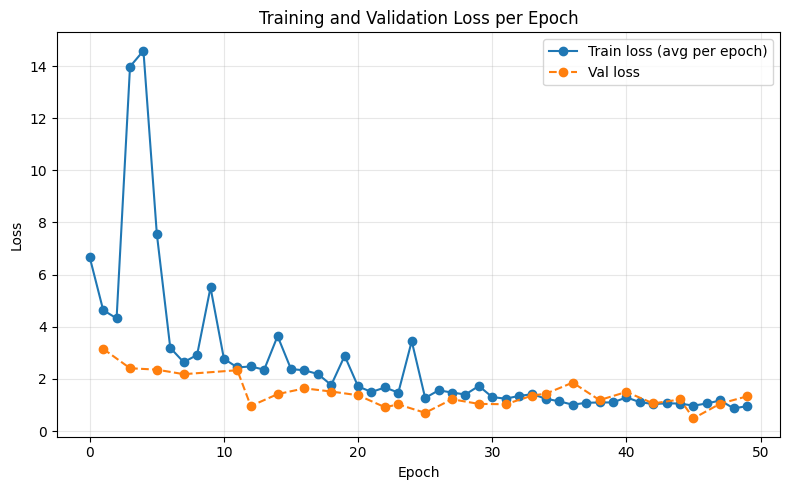
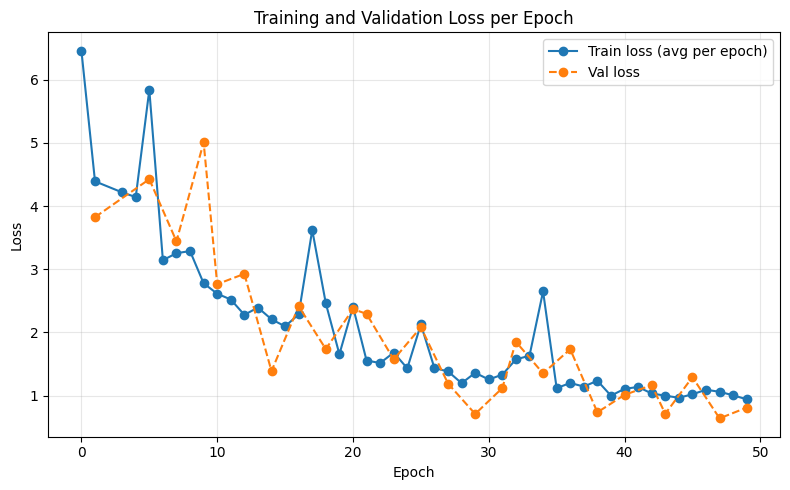
As can be seen in Figures 2 and 3, the baseline GETMusic model converges much faster than the MTL model, which is likely due to an overfit on limited training data.
Results & Analysis
In our experiments, both the baseline and modified models were prompted to generate a piano accompaniment track conditioned on the fixed lead-voice track. This setup isolates the effect of our changes on harmonic behavior, since the melodic line remains constant across models. We ran inference on 50 tracks from Slakh2100's cleaned test set.
After generation, we ran an interval-analysis script that compares the piano part to the lead voice at each timestep and records the music-theoretic intervals formed between the two. This allowed us to quantify how often each interval class appears and whether the model shifts toward more consonant, stylistically appropriate harmonies.
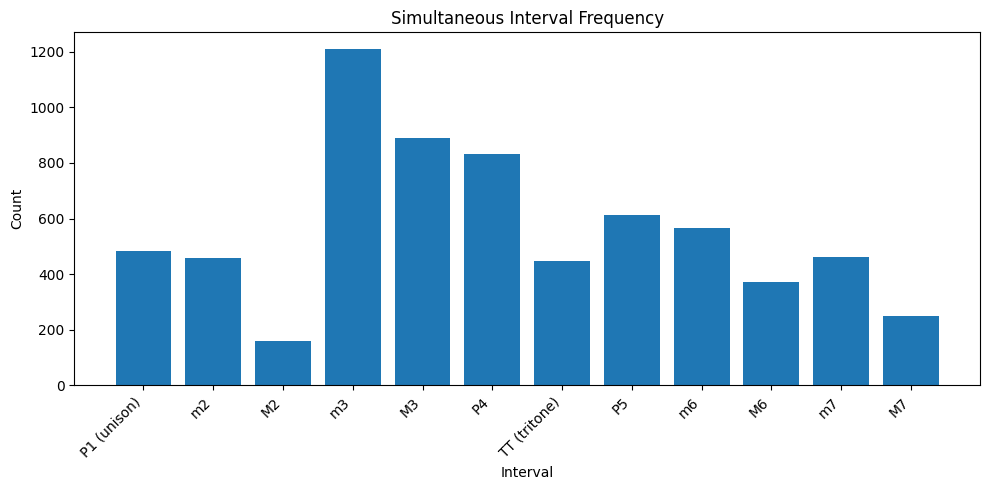
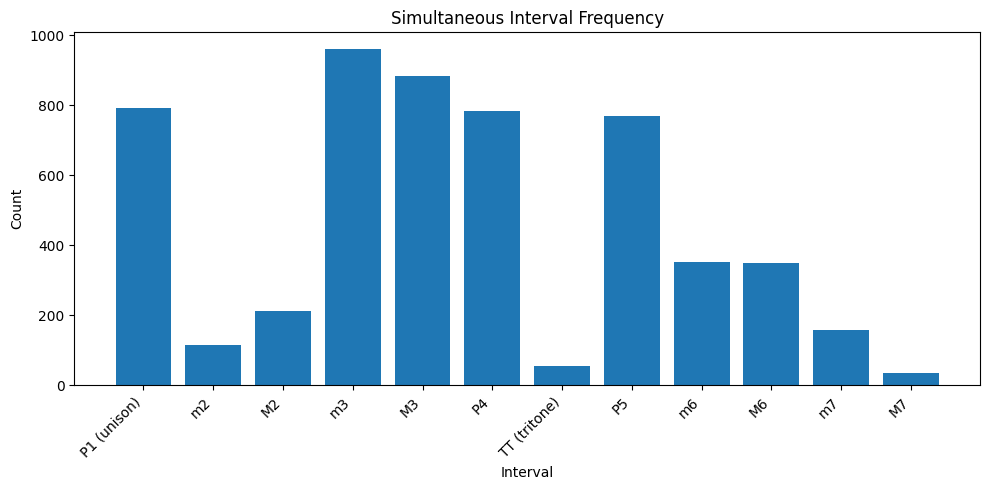
To visualize these differences, we computed frequency distributions of all intervals (unisons, thirds, fifths, etc.) for both the baseline and test models, included below.
Qualitative
We provide sample MIDIs that were generated by the original model and our modified model.
Original loss:
Music theory-based loss:
In this example, we can see that the model using a music theory-based loss function does a slightly better job of generating a leading melody which maintains coherent vertical harmony. The music theory-based loss emphasizes the inclusion of more triads like the first G major chord you hear so clearly in the beginning. Some other stylistic differences can be discerned between the two recordings, such as the increased dissonance in the first recording and clashing of multiple tracks and instruments. Our loss function seems able to guide the model to prioritize inter-track harmony through the vertical consonance and key adherence loss components. However, given the sparsity of data and difficulty in objectively evaluating something as subjective asmusic, we turn to quantitative metrics.
Quantitative
We also wanted to quantitatively assess the differences in the model outputs. We ran an interval-analysis script that compares the piano part to the lead voice at each timestep and records the music-theoretic intervals formed between the two. This allowed us to quantify how often each interval class appears and whether the model shifts toward more consonant, stylistically appropriate harmonies.
As can be seen in Figures 4 and 5, the music theory-based loss function creates a higher frequency of perfect intervals (unison, perfect fourth, perfect fifth) as well as major and minor thirds. On the other hand, the baseline generated a more diverse spread of intervals. This makes sense given our loss function; the key adherence loss in particular emphasizes maintaining regular intervals between adjacent notes.
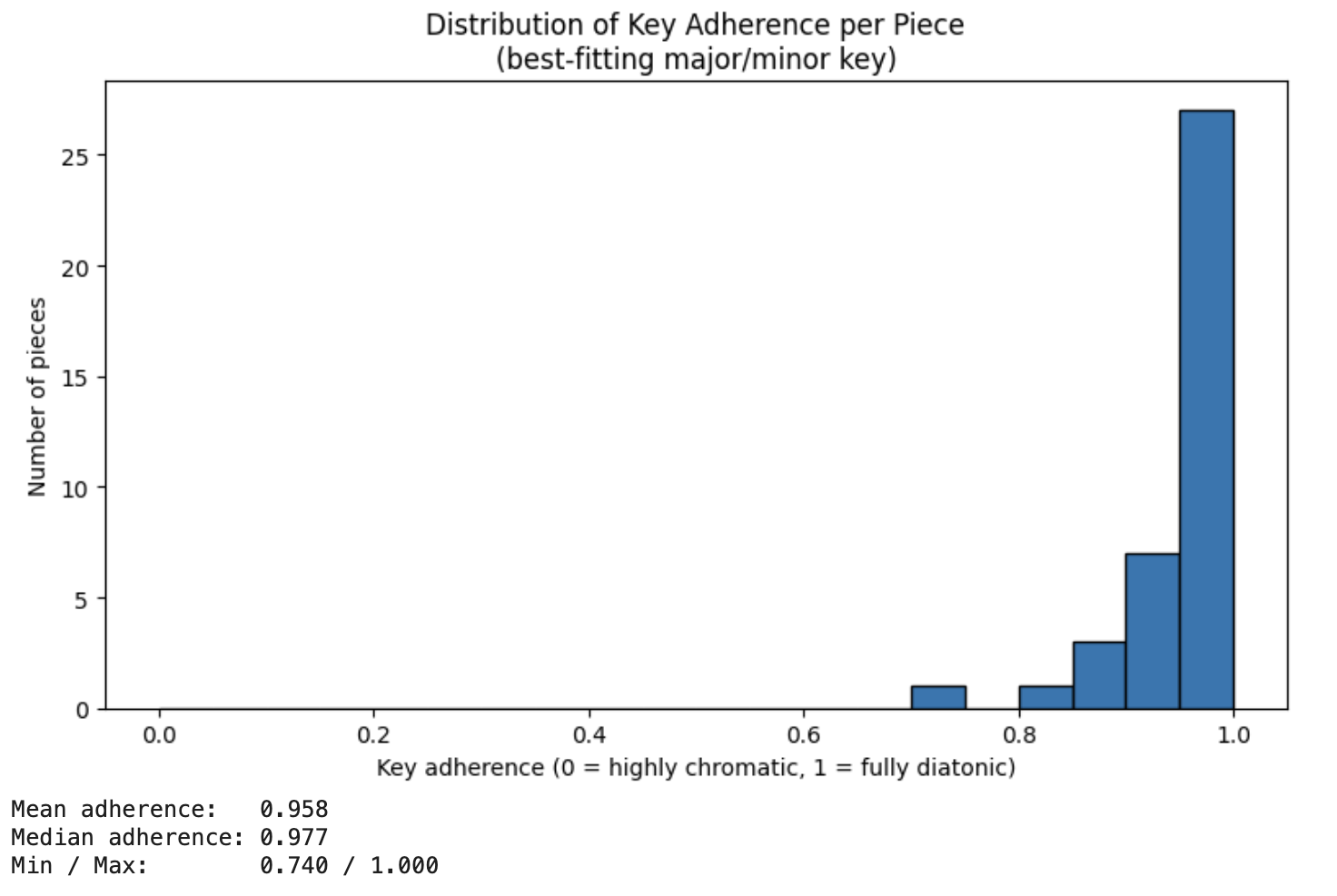
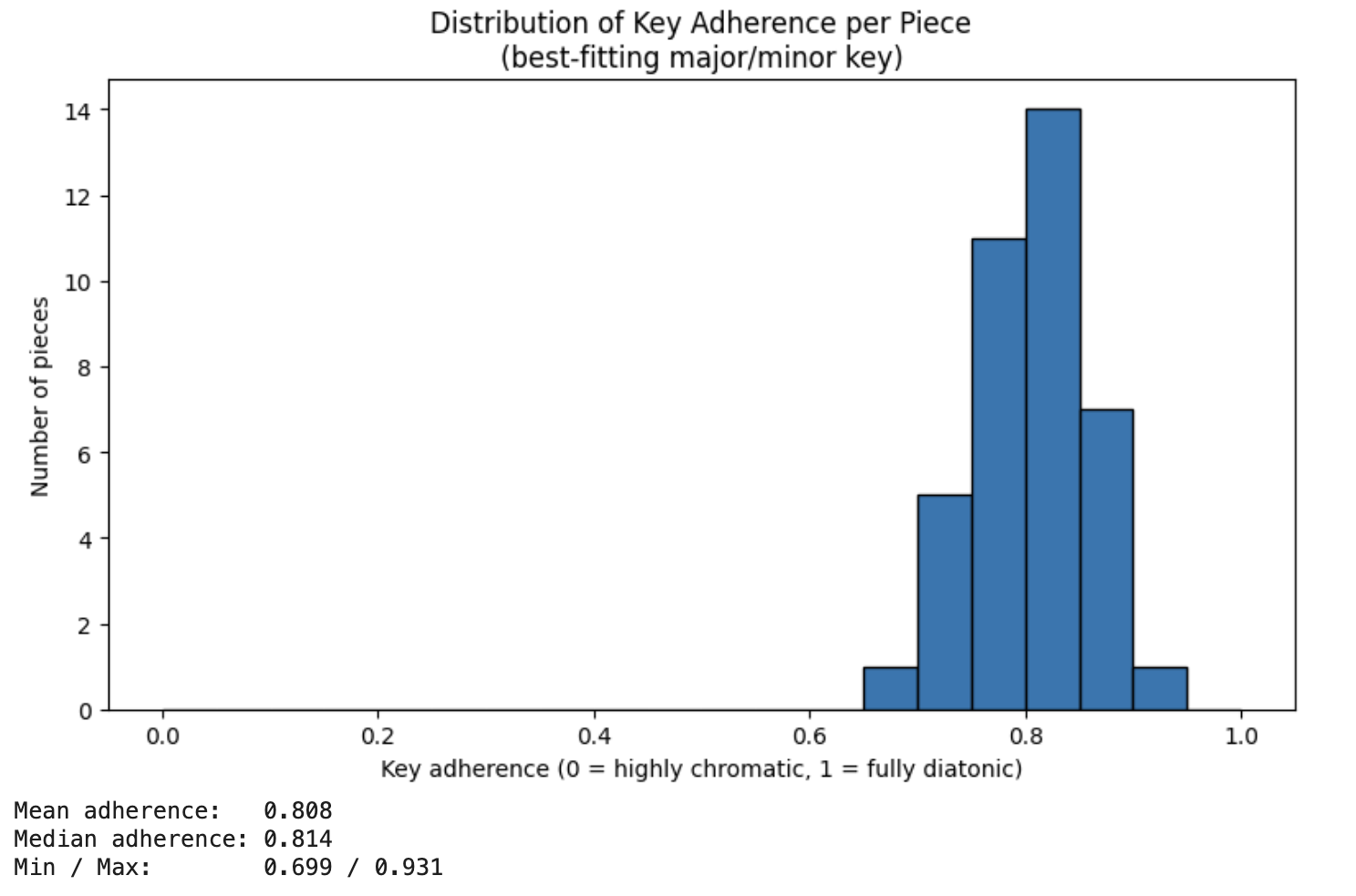
We also looked at the distribution of key adherence per piece. We inferred the global key of a MIDI piece by selecting the major or minor key whose rotated Krumhansl–Schmuckler profile - a fixed distribution for the number of occurrences of each note in a specific key - best matched the piece's pitch-class histogram. Key adherence was then computed as the proportion of all notes whose pitch classes fall within the diatonic scale of that inferred key. As shown in Figures 6 and 7, we found that the key adherence was stronger in the baseline model rather than the MTL model. This was not an intended outcome, which we explain in more detail in the conclusion.
Conclusions
Our preliminary experiments suggest that explicitly encoding simple harmonic priors into the loss can improve symbolic polyphonic generation in low-data settings, while remaining compatible with the existing GETMusic architecture.
A key limitation of our current setup is the capacity/data mismatch: the architecture is quite powerful relative to the amount of high-quality symbolic data we were able to curate. In practice, scaling the dataset is non-trivial; finding open source data, cleaning MIDI files, and normalizing instrumentation proved to be some of the most technically challenging aspects of our process. Despite adding stronger inductive biases to partially compensate for limited data, these constraints still cap how reliably the model can internalize harmonic structure.
Going forward, we see several directions. First, we plan to broaden the family of music-theory loss terms beyond the current key-adherence–style regularizer, including transposition-invariance losses that encourage similar predictions under global key shifts, discouraging extreme leaps, chord and progression losses based on functional harmony or circle-of-fifths proximity, as well as metrical and phrasing losses, such as downbeat chord stability, and preference for chord changes on strong beats. Second, our evaluation was constrained by the stylistic and structural limitations of the datasets we used. Because our training data focused on a narrow range of genres and track configurations, we were unable to exploit the rich diversity found in classical corpora such as Bach chorales, SATB a cappella scores, or multi-instrument orchestral datasets. Likewise, our testing primarily centered on a fixed subset of tracks, leaving rhythmic components—especially drums—underexplored. Broadening the stylistic scope and incorporating datasets with more varied harmonic and rhythmic profiles would likely improve the model's ability to generalize across musical textures.
By systematically tuning these weights and progressively enriching the theory-aware loss portfolio—while also investing in larger, cleaner symbolic corpora—we expect future iterations to make more consistent use of musical structure, even under data-constrained settings.
References
- H. Wang, Y.-N. Chen, Z. Huang, et al. MusicGen: Generating High-Fidelity Music from Text. arXiv:2406.00146, 2024. Available at: https://arxiv.org/abs/2406.00146.
- Suno AI. Suno: Text-to-Music Generation Platform. Available at: https://suno.com/home.
- Z. Lv, Z. Dai, G. Li, et al. GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework. arXiv:2305.10841, 2023.
- N. Boulanger-Lewandowski, Y. Bengio, and P. Vincent. Modeling Temporal Dependencies in High-Dimensional Sequences: Application to Polyphonic Music Generation and Transcription. In Proceedings of the 29th International Conference on Machine Learning (ICML), 2012. arXiv:1206.6392.
- C.-Z. A. Huang, A. Vaswani, J. Uszkoreit, et al. Music Transformer: Generating Music with Long-Term Structure. In International Conference on Learning Representations (ICLR), 2019. arXiv:1809.04281.
- W.-Y. Hsiao, J.-Y. Liu, Y.-H. Yang, and I. Liao. Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs. In AAAI Conference on Artificial Intelligence, 2021. arXiv:2101.02402.
- Y. Ren, J. He, X. Tan, et al. PopMAG: Pop Music Accompaniment Generation. In Proceedings of the 28th ACM International Conference on Multimedia, 2020. arXiv:2008.07703.
- J. Ens and P. Pasquier. MMM: Exploring Conditional Multi-Track Music Generation with the Transformer. In Proceedings of the 21st International Society for Music Information Retrieval Conference (ISMIR), 2020. arXiv:2008.06048.
- H.-W. Dong, K. Chen, S. Dubnov, J. McAuley, and T. Berg-Kirkpatrick. Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments. In ICASSP, 2023. arXiv:2207.06983.
- K. Ryu, S. Cho, H. Choi, et al. Nested Music Transformer: Sequentially Decoding Compound Tokens in Symbolic Music. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2024. arXiv:2408.01180.
- H.-W. Dong, W.-Y. Hsiao, L.-C. Yang, and Y.-H. Yang. MuseGAN: Multi-Track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment. In Proceedings of the AAAI Conference on Artificial Intelligence, 2018. arXiv:1709.06298.
- L.-C. Yang, S.-Y. Chou, and Y.-H. Yang. MidiNet: A Convolutional Generative Adversarial Network for Symbolic-Domain Music Generation. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), 2017. arXiv:1703.10847.
- K. W. Cheuk, R. Sawata, T. Uesaka, et al. DiffRoll: Diffusion-based Generative Music Transcription with Unsupervised Pretraining Capability. In ICASSP, 2023. arXiv:2210.05148.